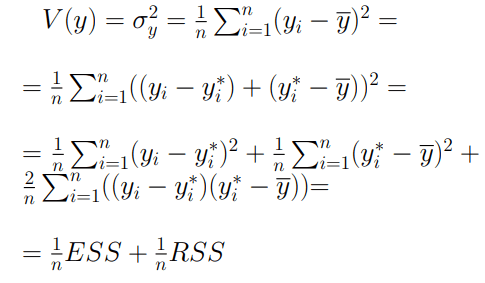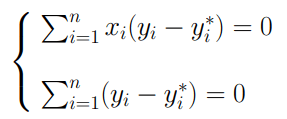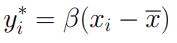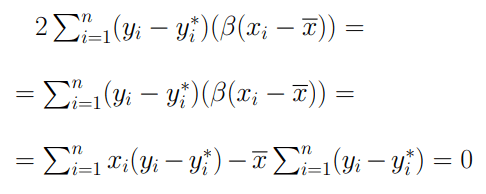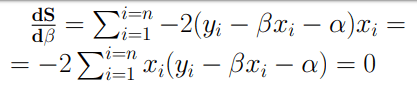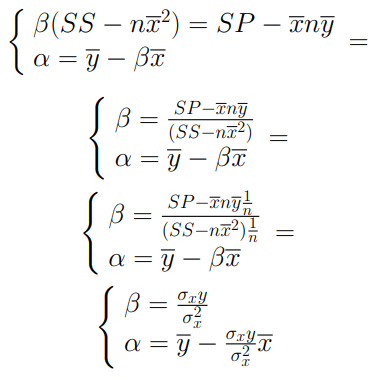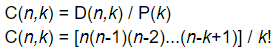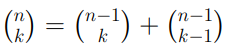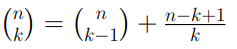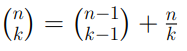Consideriamo un generico valore intero n e la sua traduzione sotto forma di sequenze di bit: quello che vogliamo è determinare il valore assunto dal bit che occupa la prima posizione partendo da destra. In base a quanto detto nell’articolo relativo ai codici binari, il valore che stiamo cercando sarà quello meno significativo e prende perciò il nome di LSB. Per capire come raggiungere il nostro obiettivo consideriamo un generico numero intero n tradotto in sequenza di bit: 1010101. Il metodo più semplice che ci porta alla soluzione cercata consiste nell’utilizzo del comando “and” tra n ed il valore 1: come sappiamo, infatti, questo comando restituisce 1 se i bit che occupano la stessa posizione tra n ed 1 sono uguali, altrimenti restituirà 0. Pertanto avremo il seguente output
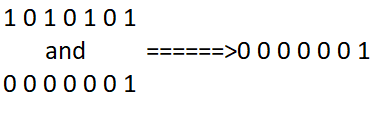
Possiamo concludere affermando che questo metodo applica una maschera ai primi 6 bit lasciando invariato quello che ci interessava.
Il comando “and” che abbiamo appena visto ci ha permesso di individuare il bit meno significativo di un generico valore n. Adesso consideriamo un altro metodo utilizzato nelle operazioni bitwise che consiste nell’azzeramento del primo 1 partendo da destra di un generico valore n. Per comprendere il funzionamento di questo metodo consideriamo la sequenza di numeri interi:

La figura appena introdotta ci permette di notare alcune importanti differenza tra un numero intero n ed il suo precedente (n-1).Qual è la relazione che li lega? Il passaggio da n-1 ad n comporta la sostituzione del primo bit pari a 0 in n-1 con un bit pari a 1 in n. Inoltre, questo incremento renderà pari a 0 tutti i bit che si trovano alla destra di quello appena modificato mentre quelli che si trovano alla sua sinistra rimarranno inalterati. Per comprendere questo ragionamento è sufficiente osservare come varia la sequenza di bit quando si passa, ad esempio, da 3 a 4. Vediamo adesso come questa relazione risulti essere fondamentale per raggiungere il nostro obiettivo. Se eseguissi il comando and tra n e n-1 i valori a sinistra del bit trasformato in 1 a causa dell’incremento rimarrebbero invaiati mentre quelli alla sua destra sarebbero pari a 0: quindi avrei in output un valore uguale ad n con la differenza che al posto dell’1 selezionato avrei 0. Facciamo un esempio tra 3 e 4:

Quello che abbiamo ottenuto, pertanto, è stato ‘azzeramento del primo bit pari ad 1 di n.
Supponiamo, adesso, di voler contare il numero di bit uguali a 1 nella rappresentazione binaria di n. Così come abbiamo fatto per i precedenti operatori bitwise affiancheremo alla spiegazione un esempio, in modo tale da rendere più facile la comprensione del procedimento. Indichiamo, quindi , un valore n sotto forma di sequenza binaria: 10101101. Per contare il numero di bit pari ad 1 contenuto in n esistono diversi metodi. Quello più semplice consiste nell’utilizzare la relazione tra n ed 1 enunciata all’inizio di questo articolo: in questo modo sarà possibile visionare il primo bit di destra di n e, nel caso in cui fosse pari ad 1, verrà contato. Una volta fatto questo utilizziamo degli operatori di shift per traslare verso destra la sequenza di n, eliminando in questo modo il bit precedentemente visionato. Eseguendo iterativamente questo processo riusciremo a contare i bit pari ad 1 contenuti in n. Consideriamo adesso un nuovo algoritmo che restituisce lo stesso output di quello appena descritto ma che risulta essere più rapido di quello naive. Per questo secondo algoritmo ,che prende il nome di Algoritmo di Kernighan, dovremo utilizzare la relazione esistente tra n ed n-1. Notiamo subito come questo algoritmo presenti un numero di passaggi inferiori rispetto a quello naive: si passa, infatti, dal numero di bit al numero di bit pari ad 1. Questo perché in ogni n and n-1 resetto il bit=1 più a destra. quindi questo algoritmo consiste nel loop di n and n-1.
Altra operazione bitwise: nel caso in cui il comando n and n-1 restituisse 0 come soluzione potremmo affermare che n è una potenza di 2.
Consideriamo adesso l’operatore shift. Se eseguissi un comando shift verso destra otterrei che ad ogni 1 del nostro n risulterà associata una potenza inferiore (da 2^k a 2^(k-1)): viene divisa, quindi per 2. Questa divisione per 2 avviene solo se il numero di partenza è pari: in contrario perderemmo il primo bit di destra. Si verifica quindi una divisione troncata: con lo shift prendo la parte intera di n/2. Facciamo un esempio:
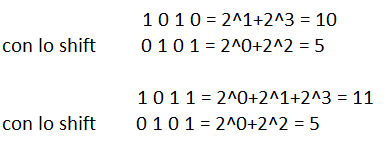
Se avessi eseguito lo shift verso sinistra avrei avuto una situazione opposta. Ovviamente è possibile eseguire di k e non necessariamente di 1: in quel caso avrei ottenuto delle modifiche di 2^k con k positivo o negativo a seconda della direzione dello shift.
Altra operazione: n or 1

Se il numero n è dispari non si modifica mentre se è pari viene incrementato di n: il comando or trasforma n nel primo intero dispari maggiore o uguale di sé.
Altro problema risolto dagli operatori bitwise: partendo da un numero intero n voglio trovare la più grande potenza di 2 lo divide. Detto in modo diverso, voglio essere in grado di esprimere n come 2^k*D dove D è l’intero dispari che residua come fattore. Facciamo un esempio, ponendo n=12 possiamo scomporlo nel prodotto tra 2 e 6, dove 6 più essere a sua volta espresso come prodotto di 2*3. Quindi in questo caso n risulta essere pari a 2^2*3 e pertanto la massima potenza che divide n sarà pari a 2. Ovviamente, se n fosse dispari la potenza massima che stiamo cercando sarebbe pari a 0. Un primo procedimento è stato appena descritto nell’esempio ma ora useremo gli operatori bitwise e la particolare struttura di n-1. Prendiamo in esame un generico numero pari (101000): esso sarà pari a 2^3*(1+2^2) e perciò la sua potenza massima risulta essere pari a 3. Il valore appena ottenuto coincide con la potenza del bit che ha assunto valore pari ad 1 mediante il passaggio da n-1 a n. Eseguendo il comando “not” su n-1 mediante il quale invertiamo gli 1 e gli 0. Questa modifica risulta fondamentale perché eseguendo in comando and tra n e not(n-1) riusciremo a spianare tutti i valori che si trovano alla sinistra del bit modificato a causa dell’incremento in modo tale che rimanga solo l’1 associato alla potenza massima di n.

dove k rappresenta la massima potenza di n.